/ tedamoh
Coaching,
Academy &
Consulting.
Ein neues Datenmodell für das Data Warehouse ist notwendig, aber wie modelliert man Daten? Temporale Daten verstehen und dazu Methoden und Techniken erlernen? Oder eine Zertifizierung zur Datenmodellierung?
Bei all dem unterstützen wir mit Coaching, unserer Academy oder mit Consulting!


/ NEWS
Get the latest updates
Our latest updates of all categories - including our blog articles.
Data Warehouse
-
Data Modeling Zone Europe 2015

Do you want to learn something about data modelling with Steve Hoberman? You want to explore new methods like Data Vault 2.0, Anchor Modeling, Data Design, DMBOK and many more? E.g. a keynote where Dan Linstedt, Lars Rönnbäck and Hans Hultgren talks together, and another one with Bill Inmon?
-
Data Vault - Datenmodellierung noch notwendig?

Wie bereits in meinem Blogpost Modellierung oder Business Rule beschrieben ist es notwendig sich bei der Datenmodellierung über Geschäftsobjekte, die Wertschöpfungskette, fachliche Details und die Methodik des Modellierens einige Gedanken zu machen.
Oder doch nicht? Kann ich mit Data Vault einfach loslegen? Schließlich ist Data Vault auf den ersten Blick ganz einfach. Drei Objekte: HUBs, LINKs und SAT(elliten), einem einfachen Vorgehensmodell und ein paar wenige Regeln. Brauche ich für Data Vault noch die Datenmodellierung?
-
Data Vault heißt die moderne Antwort

Neue Wege in der Datenmodellierung
Geschäftsanforderungen oder Business Needs verändern sich in heutigen Unternehmen in sehr kurzen Intervallen. Was gestern noch als gesetzt galt, kann morgen schon wieder vorbei sein. Fachabteilungen fordern in immer kürzeren Abständen die Bereitstellung geeigneter Daten, um Entscheidungen zu treffen. Feste und starre Regeln werden bewusst gebrochen, um etwas Neues zu entdecken. -
DBMS resource file

PowerDesigner offers the possibility to edit the properties for a database in the so-called DBMS resource files. The DMBS resource files contain all information for PowerDesigner to generate DDL, DML and other SQL artifacts. For many databases, there are pre-built, included DBMS resource files for the different database versions.
-
DBMS-Ressourcendatei
PowerDesigner bietet die Möglichkeit, die Eigenschaften für eine Datenbank in der sogenannten DBMS-Ressourcendateien zu bearbeiten. Die DMBS-Ressourcendateien enthalten alle Informationen für den PowerDesigner, um DDL, DML und andere SQL Artefakte zu generieren. Für viele Datenbanken gibt es vorgefertigte, mitgelieferte DBMS-Ressourcendateien für die unterschiedlichen Datenbankversionen.
-
Die Bedeutung von bitemporalen Daten

Ich war sehr zufrieden mit Dirk Lerners Temporal Data in a Fast-Changing World! Training. Die Schulung hat alle meine Fragen zur Bitemporalität beantwortet, die in anderen Data-Vault-Schulungen nicht so klar angesprochen wurden.
-
DMZ Europe 2016
This year’s European Data Modeling Zone (DMZ) will take place at the wonderful German capital Berlin and I’m very happy to be again speaker at this great event! This year I’ll speak about how to start with a conceptual model, using a logical model and finally how to model the physical Data Vault. During this session we will do some exercises (no, no push-ups!!) to bring our brains up and running about modeling.
-
DWH Automation - Expectations & Reality (1)

How can repeating tasks be simplified? The question of automating processes in a data warehouse (DWH) keeps project teams busy.
-
DWH Automation - Expectations & Reality (2)

The consideration of automating the processes in a data warehouse (DWH) as far as possible keeps many project teams busy today.
-
DWH Automation - Expectations & Reality (3)

The consideration of automating the processes in a data warehouse (DWH) as far as possible keeps many project teams busy today.
-
DWH Automatisierung - Erwartungen & Realität (1)
Wie können wiederkehrende Aufgaben vereinfacht werden? Die Frage nach der Automatisierung von Prozessen in einem Data Warehouse (DWH) beschäftigt Projektteams.
-
DWH Automatisierung - Erwartungen & Realität (2)
Die Überlegung einer möglichst weitgehenden Automatisierung der Prozesse in einem Data Warehouse (DWH) beschäftigt heute viele Projektteams.
-
DWH Automatisierung - Erwartungen & Realität (3)
Die Überlegung einer möglichst weitgehenden Automatisierung der Prozesse in einem Data Warehouse (DWH) beschäftigt heute viele Projektteams.
-
Enterprise Data & BI & Analytics 19 #EDBIA

I am pleased to say that I will be participating at this year’s Enterprise Data & Business Intelligence and Analytics Conference Europe 18-22 November 2019, London. I will be speaking on the subject ‘From Conceptual to Physical Data Vault Data Model’ and (for sure) on my hobby horse subject temporal data: ‘Send Bi-Temporal Data from Ground to Vault to the Stars’. See my abstracts for the sessions below.
-
Erfolg mit bitemporalem Wissen

Ich hatte gerade bei einem neuen Kunden angefangen und war Teil des Data-Warehouse-Teams, das für den Aufbau des Data Warehouse mit Data Vault verantwortlich war. Wir hatten einen Data Vault-Generator entwickelt. Damals verwendeten wir ein Enddatum für die 'business timeline'. Ich erinnere mich, wie kompliziert es war, die alten Datensätze zu aktualisieren, und wie viel Zeit das den Server kostete. Vor allem, wenn man zwischendurch Datensätze hinzufügen wollte. Zum Beispiel um die Historie aus alten Quellen zu laden.
-
Fact-Oriented Modeling

Information Modeling in Natural Language
Fact-Oriented Modeling (FOM) is a family of conceptual methods in which facts are precisely modeled as relationships with any number of arguments. This type of modeling enables easier understanding of the model because natural language is used to create the data model. This also fundamentally differentiates FOM from all other modeling methods. This approach sounds new and exciting. However, it goes back to the 1970s in its basic features. -
Fact-Oriented Modeling (FOM) - Family, History and Differences
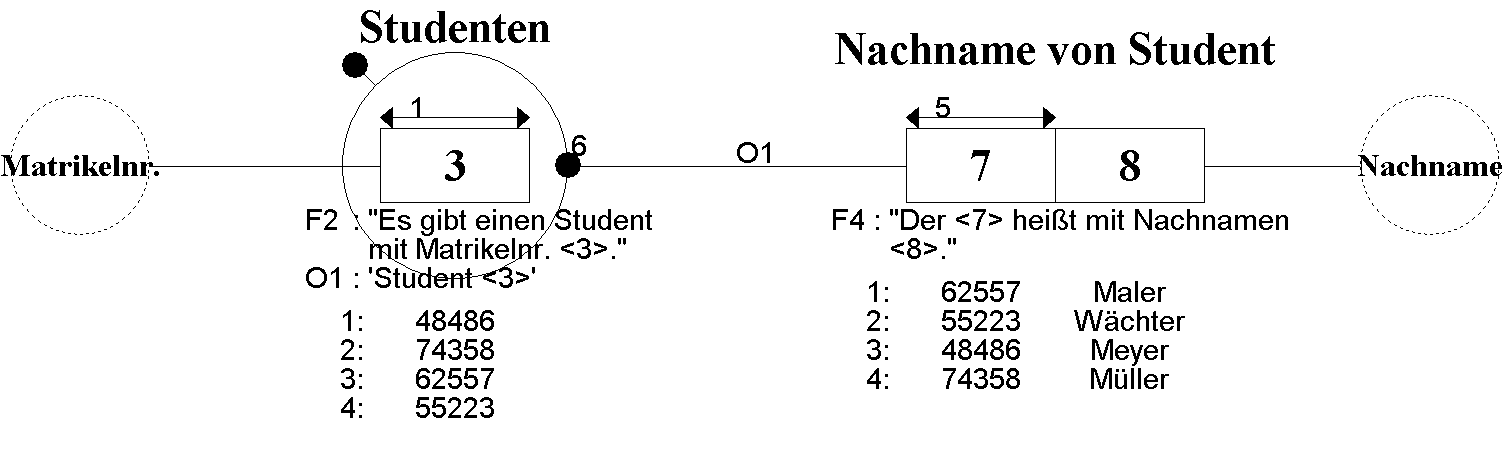
Months ago I talked to Stephan Volkmann, the student I mentor, about possibilities to write a seminar paper. One suggestion was to write about Information Modeling, namely FCO-IM, ORM2 and NIAM, siblings of the Fact-Orietented Modeling (FOM) family. In my opinion, FOM is the most powerful technique for building conceptual information models, as I wrote in a previous blogpost Sketch Notes Reflections at TDWI Roundtable with FCO-IM.
-
Faktenorientierte Modellierung
Information Modeling in natürlicher Sprache
Fact-Oriented Modeling (FOM) ist eine Familie von konzeptuellen Methoden, bei denen die Fakten präzise als Beziehungen mit beliebig vielen Argumenten modelliert werden. Diese Art der Modellierung ermöglicht ein einfacheres Verständnis des Modells, da zur Erstellung des Datenmodells natürliche Sprache verwendet wird. Dies unterscheidet FOM auch grundlegend von allen anderen Modellierungsmethoden. Dieser Ansatz hört sich neu und spannend an. Er geht jedoch in Grundzügen bereits in die 1970er-Jahre des vorigen Jahrhunderts zurück. -
FCO-IM at TDWI Roundtable
FCO-IM - Data Modeling by Example
Do You want to visit a presentation about Fully Communication Oriented Information Modeling (FCO-IM) in Frankfurt?
I’m very proud that we, the board of the TDWI Roundtable FFM, could win Marco Wobben to speak about FCO-IM. In my opinion, it’s one of the most powerful technique for building conceptual information models. And the best is, that such models can be automatically transformed into ERM, UML, Relational or Dimensional models and much more. So we can gain more wisdom in data modeling at all.But, what is information modeling? Information modeling is making a model of the language used to communicate about some specific domain of business in a more or less fixed way. This involved not only the words used but also typical phrases and patterns that combine these words into meaningful standard statements about the domain [3].
-
Flashback to the 38th TDWI Roundtable in Frankfurt

Our roundtable in Frankfurt in March started with a bang:
Marketing for BI is even lower in the priority order than documentation.

Weiterlesen …Das Training ist sehr zu empfehlen, weil die Komplexität und der Mehrwert der Modellierung deutlich wird. Zudem ist es umfangreich und deckt alle Modellierungsaspekte ab. Modellierung nutzt jedem!

Weiterlesen …Der Wissensaufbau im Team, die Identifikation mit und das Vertrauen in das Datenmodell sind entsprechend hoch. Das ist sehr gut, denn auf unserem Weg, ein datengetriebenes Unternehmen zu werden, stehen wir vor großen Herausforderungen.

Weiterlesen …Historisierungs-Grundlagen werden ausführlich theoretisch erläutert und anhand praktischer Übungen sofort verprobt, super!

Weiterlesen …Dirk Lerner ist mit seiner Expertise als Coach für Data Vault und flexiblen Data Warehouse Architekturen uneingeschränkt zu empfehlen.