
Künstliche Intelligenz revolutioniert gerade nahezu jeden Geschäftsbereich. Doch bei aller Begeisterung für diese Technologien wird dabei oft ein fundamentales Paradox übersehen: KI benötigt hochwertige, strukturierte Daten, um überhaupt funktionieren zu können. Gleichzeitig ist ausgerechnet KI selbst nicht in der Lage, die Datenstrukturen zu schaffen, die sie zum Arbeiten braucht.
Künstliche Intelligenz revolutioniert gerade nahezu jeden Geschäftsbereich – von der Produktentwicklung über das Marketing bis zur Logistik. Unternehmen investieren Millionen in Machine Learning Modelle, Predictive Analytics und generative KI-Anwendungen. Doch bei aller Begeisterung für diese Technologien wird dabei oft ein fundamentales Paradox übersehen: KI benötigt hochwertige, strukturierte Daten, um überhaupt funktionieren zu können. Gleichzeitig ist ausgerechnet KI selbst nicht in der Lage, die Datenstrukturen zu schaffen, die sie zum Arbeiten braucht.
Serie: KI-gestützte Datenmodellierung | Teil 1 von 4
 The AI Paradox
The AI ParadoxWarum Datenmodellierung das Fundament jeder KI ist
Bevor ein KI-System aussagekräftige Muster erkennen, Vorhersagen treffen oder Empfehlungen aussprechen kann, braucht es Daten mit drei grundlegenden Eigenschaften: Sie müssen von hoher Qualität sein, klar strukturiert vorliegen und leicht zugänglich sein. Genau diese Eigenschaften werden durch professionelle Datenmodellierung sichergestellt.
Was macht ein gut durchdachtes Datenmodell? Es definiert, welche Geschäftsobjekte existieren, wie sie miteinander in Beziehung stehen, welche Attribute sie haben und welche Regeln für die Verwendung gelten. Es sorgt dafür, dass "Kunde" immer nach den gleichen Kriterien definiert wird, dass Zeitstempel einheitlich formatiert sind und dass Beziehungen zwischen Entitäten nachvollziehbar bleiben. Ohne diese Grundlage produzieren selbst die ausgefeiltesten Algorithmen bestenfalls Zufallsergebnisse – schlimmstenfalls treffen sie systematisch falsche Entscheidungen, weil sie auf inkonsistenten oder fehlerhaften Daten trainiert wurden.
Customer 360: Wenn fehlende Struktur zum Business-Problem wird
Nehmen wir ein konkretes Beispiel aus der Praxis: FastChangeCo, ein fiktives Handelsunternehmen, betreibt sowohl Filialen als auch einen Online-Shop und möchte seinen Kunden personalisierte Angebote unterbreiten. Die Idee klingt simpel: Eine KI analysiert das Kaufverhalten und macht passende Produktvorschläge. In der Realität stößt dieses Vorhaben aber schnell an Grenzen, wenn keine solide Datenmodellierung vorliegt.
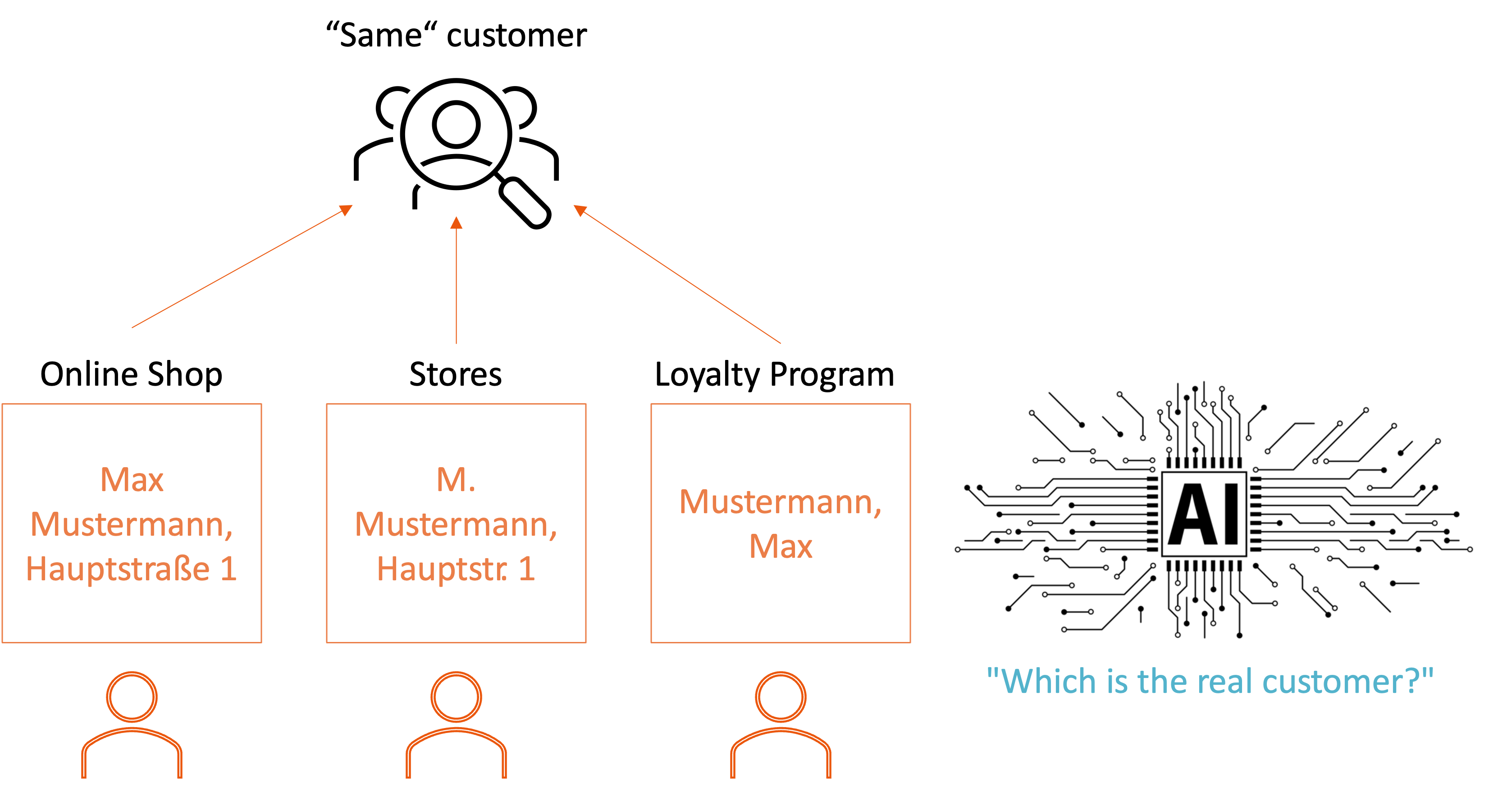 Customer 360 - Das ProblemDie Kundendaten bei FastChangeCo liegen in verschiedenen Systemen: Das Treueprogramm speichert Stammdaten und Punktestände, der Online-Shop verwaltet Login-Informationen und Warenkorb-Historien, die Filialsysteme erfassen Kassenbons mit Kundenkarten-Nummern. Jedes System hat seine eigene Logik, seine eigenen Formate, seine eigenen Konventionen.
Customer 360 - Das ProblemDie Kundendaten bei FastChangeCo liegen in verschiedenen Systemen: Das Treueprogramm speichert Stammdaten und Punktestände, der Online-Shop verwaltet Login-Informationen und Warenkorb-Historien, die Filialsysteme erfassen Kassenbons mit Kundenkarten-Nummern. Jedes System hat seine eigene Logik, seine eigenen Formate, seine eigenen Konventionen.
Jetzt wird es interessant: Ist "Max Mustermann, Hauptstraße 1, 60311 Frankfurt" derselbe Kunde wie "M. Mustermann, Hauptstr. 1, 60311 Frankfurt"? Oder wie "Mustermann, Max" mit abweichender Hausnummer, weil die Person inzwischen umgezogen ist?
Ohne ein klares Datenmodell, das definiert, wie Kundendaten konsolidiert werden, nach welchen Regeln Duplikate erkannt werden und wie mit Adressänderungen umgegangen wird, entstehen mehrfache Kundenprofile. Die Folge: Derselbe Kunde erhält widersprüchliche Angebote über verschiedene Kanäle, Marketingbudgets werden verschwendet, Gutscheine verfallen ungenutzt, weil sie an die falsche Profilversion geschickt wurden. Die KI, die eigentlich helfen sollte, verstärkt das Chaos nur – sie lernt aus fragmentierten Daten und trifft entsprechend unzuverlässige Vorhersagen.
Erst ein durchdachtes Datenmodell schafft die Voraussetzung für eine echte 360-Grad-Kundensicht. Es legt fest, welche Attribute einen Kunden eindeutig identifizieren, wie verschiedene Datenquellen zusammengeführt werden, welches System als "Leading System" für bestimmte Informationen gilt und nach welchen Regeln Konflikte aufgelöst werden. Auf dieser Grundlage kann die KI dann tatsächlich arbeiten – sie erkennt Kaufmuster, identifiziert Cross-Selling-Potenziale und personalisiert Angebote. Aber sie kann dieses Fundament nicht selbst schaffen.
Das Problem der unternehmensspezifischen Definitionen
Hier kommen wir zum Kern des Paradoxes: KI-Systeme sind hervorragend darin, Muster in strukturierten Daten zu erkennen. Sie können aus Millionen von Transaktionen lernen, subtile Zusammenhänge aufdecken und komplexe Vorhersagen treffen. Was sie jedoch nicht können: verstehen, was "Kunde" in einem spezifischen Geschäftskontext bedeutet.
 "Kunde" - Eine Frage der DefinitionIst ein Kunde jemand, der bereits gekauft hat? Oder reicht eine Registrierung? Zählt ein Geschäftskunde anders als ein Privatkunde? Wie wird zwischen dem Rechnungsempfänger, dem Lieferempfänger und dem Nutzer bei B2B-Geschäften unterschieden? Diese Fragen haben keine generische Antwort – sie hängen vom Geschäftsmodell, der Branche, den Prozessen und oft auch von regulatorischen Anforderungen ab.
"Kunde" - Eine Frage der DefinitionIst ein Kunde jemand, der bereits gekauft hat? Oder reicht eine Registrierung? Zählt ein Geschäftskunde anders als ein Privatkunde? Wie wird zwischen dem Rechnungsempfänger, dem Lieferempfänger und dem Nutzer bei B2B-Geschäften unterschieden? Diese Fragen haben keine generische Antwort – sie hängen vom Geschäftsmodell, der Branche, den Prozessen und oft auch von regulatorischen Anforderungen ab.
Schauen wir uns das genauer an: Eine Versicherung definiert "Kunde" fundamental anders als ein E-Commerce-Unternehmen. Bei der Versicherung ist die Unterscheidung zwischen Versicherungsnehmer und versicherter Person essentiell, während im Online-Handel die Differenzierung zwischen registriertem User, Newsletter-Abonnent und tatsächlichem Käufer entscheidend sein kann. Ein SaaS-Unternehmen wiederum denkt in Organisationen, Workspaces und individuellen Usern – eine völlig andere Struktur.
Generische KI-Modelle oder Standard-Schemas können diese Nuancen nicht abbilden. Sie arbeiten mit Durchschnittswerten und typischen Mustern, die aus öffentlich verfügbaren Daten oder branchenweiten Konventionen abgeleitet sind. Der Wettbewerbsvorteil liegt aber häufig genau in den spezifischen Definitionen und Prozessen, die ein Unternehmen von seinen Mitbewerbern unterscheiden. Ein generisches Datenmodell würde diese Differenzierung eliminieren – und damit einen Teil der Uniqueness.
Über diese Serie: Dieser Artikel ist der erste Teil einer vierteiligen Serie über KI-gestützte Datenmodellierung. In den kommenden Wochen beleuchten wir die Grenzen der KI-Automatisierung, stellen einen praxiserprobten hybriden Ansatz vor und diskutieren, wie sich die Rolle des Datenmodellierers im Zeitalter der KI verändert.
Möchten Sie mehr über professionelle Datenmodellierung lernen?
Die Grundlagen der Datenmodellierung sind essentiell, um KI-Projekte erfolgreich umzusetzen. In unserem Data Modeling Training lernen Sie, wie solide Datenmodelle entwickelt werden – das perfekte Fundament für KI-gestützte Anwendungen.
Die Hoffnung und die Realität
Die Versuchung ist natürlich groß: Könnte man nicht einfach eine KI mit bestehenden Daten füttern und sie ein Datenmodell generieren lassen? Schließlich ist KI doch so leistungsfähig geworden. Die ernüchternde Antwort lautet: Nein. KI kann Patterns erkennen, aber sie versteht keine Bedeutungen. Sie kann sehen, dass in einer Datenbank häufig die Felder "customer_name" und "customer_id" zusammen auftreten – aber sie weiß nicht, warum es in manchen Fällen zwei verschiedene Kunden-IDs für denselben Namen gibt, ob das ein Fehler ist oder eine gewollte Struktur für Haushalte.
Ein weiteres Beispiel: Eine KI könnte vorschlagen, dass "Produkt" und "Artikel" zusammengeführt werden sollten, weil sie ähnlich verwendet werden – ohne zu verstehen, dass in einem Unternehmen ein Produkt die abstrakte Marketingeinheit ist, während ein Artikel die konkrete, lagerfähige SKU darstellt. Diese semantischen Unterschiede zu erfassen, erfordert Geschäftsprozessverständnis und Domänenwissen, das Menschen mitbringen, KI-Systeme jedoch nicht.
Hinzu kommt ein weiteres fundamentales Problem: Large Language Models (LLMs) sind nicht deterministisch. Je nachdem, wie klar, exakt und spezifisch die Vorgaben und der Kontext formuliert sind, entstehen die unterschiedlichsten kreativen Varianten als Ergebnis. Auf den ersten Blick mögen diese Vorschläge korrekt erscheinen – doch im Detail oder im größeren Zusammenhang des Unternehmenskontexts können sie völlig unbrauchbar sein. Was heute als Lösung vorgeschlagen wird, kann morgen bei gleicher Anfrage ein anderes Ergebnis liefern. Diese Inkonsistenz macht LLMs als alleinige Grundlage für strategische Datenmodellierungs-Entscheidungen ungeeignet.
Ich empfehle euch Marcos Artikel über das „Titanic-Datenmodell”, der schön das nicht-deterministische Verhalten von LLMs aufzeigt!
Wie geht es weiter?
Ein wichtiger Hinweis vorab: Diese Artikel-Serie ist nicht als erschöpfende Darstellung zu verstehen, sondern als Anregung zum Nachdenken und als Startpunkt für eigene Überlegungen. Die Entwicklung im Bereich KI verläuft derzeit so rasant, dass in wenigen Monaten durchaus vieles anders aussehen kann. Die hier beschriebenen Prinzipien und Grundsatzfragen bleiben jedoch relevant – unabhängig davon, welche neuen Tools oder Ansätze entstehen.
Heißt das nun, dass KI für die Datenmodellierung vollkommen nutzlos ist? Keineswegs. Die Frage ist nicht, ob KI helfen kann, sondern wie sie richtig eingesetzt wird. Während KI nicht in der Lage ist, die strategischen Entscheidungen über Geschäftsobjekte und deren Definitionen zu treffen, kann sie Datenmodellierer in vielen anderen Bereichen erheblich unterstützen.
Im nächsten Artikel dieser Serie schauen wir uns genauer an, warum selbst modernste KI-Systeme bei der Definition von "Kunde", "Produkt" oder "Transaktion" scheitern müssen – und welche grundsätzlichen Grenzen der generischen Automatisierung dabei eine Rolle spielen. Nur wer diese Grenzen versteht, kann KI dort einsetzen, wo sie tatsächlich Mehrwert schafft.