
On July 15, Mathias Brink and I ran a webinar about Data Vault on EXASOL, modeling and implementation. The webinar started with an overview of the concepts of Data Vault Modeling and how Data Vault Modeling enables agile development cycles. Afterwards, we showed a demo that transformed the TPC-H data model into a Data Vault data model and how you can then query the data out of the Data Vault data model. The results were then compared with the original queries of the TPC-H.
As promised, here are the materials and step-by-step instructions.
(Update December 2016: Read also my blogpost Follow Up Data Vault EXASOL Webinar which answers a lot of questions)
First, if you want to follow the demo, download the free trial of EXASOL's Community Edition. Follow the instructions on how to install the virtual machine and how to use EXAplus to execute the statements.
After installing EXASOL, log in and follow the instructions as detailed in my blog post Generating large example data with TPC-H in order to build the TPC-H source data model and load sample data into EXASOL.
If you use the EXASOL Community Edition, the scale factor of the TPC-H benchmark should not exceed 10, aka 10 GB. Hint: In general, the scale factor should not exceed your database RAM.
To prepare EXASOL for the next steps, execute the following statement:
/*
Some information for the execution
It is recommended to use DB_RAM twice as tall as the scale factor of the TPC-H executed to generate the data!
E.g. scalefactor 20: DB_RAM: 40
Otherwise, please run queries two times and check the second run (Data will be in memory)
The provided check queries requires enabled auditing! Should deliver no HDD_READ for both 3nf and dv.
If hdd_read is shown, data was not in memory
disable query cache
*/
alter session set QUERY_CACHE = 'OFF';
commit;
The check queries that are provided are designed to compare the "HOT" executions and require auditing to be enabled in the EXASOL database. Auditing is enabled in EXAoperation (the administration frontend of EXASOL clusters). Simply shut down your database, click on the database where you want auditing to be enabled, click “Edit” and tick the box for auditing. Start the database afterwards. Further information on auditing can be found here.
Figure 1

To load the data into the Data Vault data model as shown in figure 1, install the DDLs from the following download link:
Incidentally, in this instance we do not differentiate between Data Vault 1.0 or 2.0. That wasn’t the goal of this webinar. If you prefer one or the other, then feel free to tweak the DML or DDL statements (If you want, I’ll publish your tweaks with credentials in this blog post).
Now you can reconstruct the steps we showed in the webinar with the DMLs provided. In the ZIP file are several DML statements ordered by a leading number and a check-query to look at the performance results. That's it!
All load-statements into Data Vault are very simple and just for single loads within this example. Don’t just copy them for your own data warehouse!
Depending on the size of data you generated for the TPC-H, you will have to adjust the filters in the statements to get the data back!
Figure 2
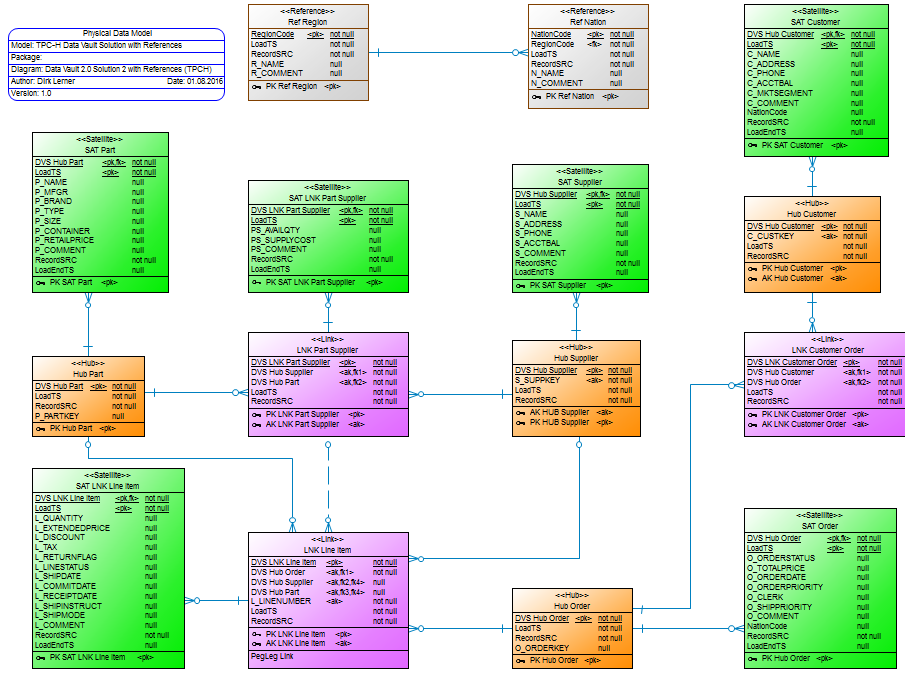
Finally, at the end of the webinar we showed you an optimized Data Vault data model (figure 2). In the following ZIP file you’ll find all the scripts you need in order to reconstruct the steps with the optimized data model. These steps are additional to above steps and the comparision SQL-file will only work if you followed all steps before.
Based on the work Mathias and I (EXASOL and ITGAIN) already did on using Data Vault with EXASOL, EXASOL's R&D team decided to implement a number of special features in the database which further optimize the performance you get when you are using EXASOL, including:
- Optimizing table elimination
- Join optimization of LINKs
- And many more
Personally, I’m thrilled to see EXASOL responding accordingly to demand and to be part of the process.
So long,
Dirk
Important notes
All SQL files that are provided are designed for a single-node EXASOL database, e.g. Community Edition. If you use those files on a cluster EXASOL database, please define proper distribution keys.
All queries are executed twice. Thereby all required indexes, statistics etc. are created by the database and the data required by a query will definitely reside in RAM for the second run.The second run is marked with the word "HOT" in the comment at the beginning of the statement.