Data Vault
-
1:M – Link: Modellierung oder Business Rule?
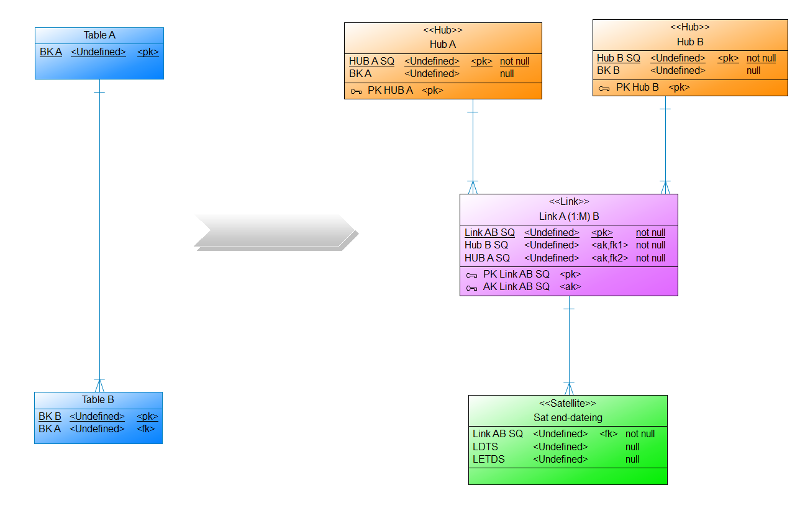
Auf dem 1. DDVUG Treffen hatten wir ein interessante Diskussion darüber, wo eigentlich die Datenmodellierung aufhört und Business Rules beginnen. Aufgehängt hatte sich dies an meiner Präsentation, in der es um einen Link ging, der eine 1:M (Hub A – (M) Link (1) – Hub B) Relation repräsentiert und über einen bi-temporalen Satelliten den gesteuert (end-dating) wird. So darf für jeden Eintrag im Hub B nur eine aktive Relation im Link existieren. Die Daten für das End-dating des Links kamen im von mir aufgeführten Beispiel bereits aus dem Quellsystem (Blogpost folgt bald).
-
1. Treffen der DDVUG

Das 1. Deutschsprachige Data Vault User Group (#DDVUG) Treffen findet auf der TDWI Konferenz2014 in München statt. Dan Linstedt wird als Ehrengast extra aus St. Albans zu unserem Treffen kommen und einen Vortrag über Data Vault halten.
Darüber hinaus wird es viele anregende Vorträge und Diskussionen aus der Praxis geben. Es soll schließlich der Austausch zwischen allen Teilnehmern gefördert, das Fachsimpeln und Netzwerken im Vordergrund stehen.
-
1. Treffen der DDVUG

Das 1. Deutschsprachige Data Vault User Group (#DDVUG) Treffen findet auf der TDWI Konferenz2014 in München statt. Dan Linstedt wird als Ehrengast extra aus St. Albans zu unserem Treffen kommen und einen Vortrag über Data Vault halten.
Darüber hinaus wird es viele anregende Vorträge und Diskussionen aus der Praxis geben. Es soll schließlich der Austausch zwischen allen Teilnehmern gefördert, das Fachsimpeln und Netzwerken im Vordergrund stehen. Dazu die Organisatoren der DDVUG:
-
13 Tipps, um Ihr Data-Vault-Projekt scheitern zu lassen

Oder wie Sie erfolgreich jede Ebene des Data Warehouse torpedieren
Sie sind erfolgsverwöhnt und haben das ewige Schulterklopfen satt? Sie wollen nicht auch noch bei Ihrem ersten Versuch zur Umsetzung eines Data-Vault-Projekts so erfolgreich sein, dass alle Kollegen neidisch werden?
-
13 tips to make your Data Vault project fail

Or how to successfully destroy every level of the data warehouse
Are you pampered with success and tired of the eternal pat on the back? You don't want to be so successful with your first attempt at implementing a Data Vault project that all your colleagues become jealous?
-
18. TDWI Roundtable Frankfurt

Ende April habe ich, als Head of Competence – Agile Data Warehousing bei BLUEFORTE, einen Vortrag über Data Vault beim 18. TDWI Roundtable in Frankfurt/Main gehalten. Die Atmosphäre war super, die Organisation durch das TDWI toll und das Publikum ist mit Leidenschaft in Diskussionen eingestiegen.
-
2. Treffen der DDVUG
Das 2. Treffen der Deutschsprachigen Data Vault User Group(#DDVUG) Treffen findet im Anschluss an die Data Modeling Zone (#DMZone14) 20141) in Hamburg statt.
Merkt euch daher unbedingt den 1. Oktober 2014 vor!
-
5th anniversary of TEDAMOH

Dear readers of my blog,
five years ago a long cherished idea of mine became reality. On July 1, 2017, TEDAMOH saw the light of day.
-
Academy
With our TEDAMOH Academy we offer various seminars, trainings and workshops to support and develop continuous learning in your daily business.
You can either extend you theoretical knowledge by attending a seminar or work in practically oriented workshops to acquire knowledge by yourself. To train the usage of a new software or method, such as dealing with temporal data, it is best to have a closer look at the training area.
-
Agile Data Warehousing bei Binck

Im April 2013 war ich wieder beim Matter-Programm, Data Vault Architecture, in den Niederlanden wo ich Tom Breur kennen lernen durfte.
In einer angeregten Diskussion über die Automatisierung von Data Warehousing mit Data Vault und der Eignung von Projektmethoden dafür lud Tom mich und Oliver Cramer zu einem Besuch von einem Kunden von sich ein: Der BinckBank.
Tom Breur: “The best Agile BI shops I have ever seen.”
Am 24. September 2013 war es dann soweit. Wir besuchten gemeinsam mit Tom die BinckBanck in Amsterdam und schauten uns das Agile Data Warehouse an, welches mit Data Vault aufgebaut wurde. Wir trafen uns mit dem BICC-Team, um über die Entstehungsgeschichte, die Umsetzung, die Herausforderungen und die Erfolgsfaktoren zu sprechen.
-
An open and honest feedback on “13 tips …”

A few weeks ago I received a surprisingly open and honest feedback on my recently published article "13 tips...". I never ever expected that! After a short email exchange, I was allowed to publish the feedback anonymously. Below is the incredible feedback[3]. You see, you are not alone with the challenges of a Data Vault project:
Hi Dirk
Thanks for sending me the English version of the paper. I'm based in […] [1] and Data Vault is not generally established here yet. -
Andventorial - Die moderne Antwort

Adventorial - Ein Online Themen Special Data Vault
Geschäftsanforderungen oder neudeutsch gesprochen Business Needs verändern sich in heutigen Unternehmen in sehr kurzen Intervallen. Was gestern noch als gesetzt galt, kann morgen schon wieder vorbei sein. Fachabteilungen fordern in immer kürzeren Abständen die Bereitstellung geeigneter Daten, um Entscheidungen zu treffen. Feste und starre Regeln werden bewusst gebrochen, um etwas Neues zu entdecken. -
Articles
All articles I wrote about data warehousing, Data Vault, data modeling and more.
Enjoy reading and your comments are welcome.
-
Bitemporal Affront
Or the battle announcement of the incoming interface
The BI Center of Competence (CoC) has decided to use bitemporal data storage when setting up a new data warehouse for one of the business units of the fictitious company FastChageCo™.
BI CoC is well advanced in the bitemporal implementation of Data Vault database objects as well as loading patterns. The already connected systems via formally defined incoming interfaces have worked without problems so far.
-
Bitemporal Data
If everything would happen at the same time, there would be no need to store historic data. We, the consumers of data, would know each and everything at the same instant. Beside all the other philosophical impacts, if time wouldn’t exists, is data still necessary?
(Un)fortunately time exists and data architects, data modelers and developers have to deal with it in the world of information technology.
In this category about temporal data I will collect all my blogposts about this fancy topic.
-
Bitemporal Data Marts

Since more than 15 years I’m working with bitemporal data in Data Warehouse solutions. Meanwhile it is easy to design, build and populate tables for bitemporal data. But how to design and build bitemporal dimensional modeled Data Marts was new to me. Dirk Lerner does a very good job in explaining complex bitemporal stuff.
-
Bitemporale Data Marts

Seit mehr als 15 Jahren arbeite ich mit bitemporalen Daten in Data Warehouse Lösungen. Mittlerweile ist es einfach, Tabellen für bitemporale Daten zu entwerfen, zu erstellen und zu befüllen. Aber wie man bitemporale dimensional modellierte Data Marts entwirft und aufbaut, war mir neu. Dirk Lerner leistet eine sehr gute Arbeit bei der Erklärung komplexer bitemporaler Daten.
-
Blog
-
CDC verstehen, um Daten in Data Vault zu löschen

Change Data Capture erkennt Änderungen an Daten. Im Falle von gelöschten Daten stellt sich die Frage: Wie sollten wir Löschungen in Data Vault verwalten?
-
Constraints im Data Vault
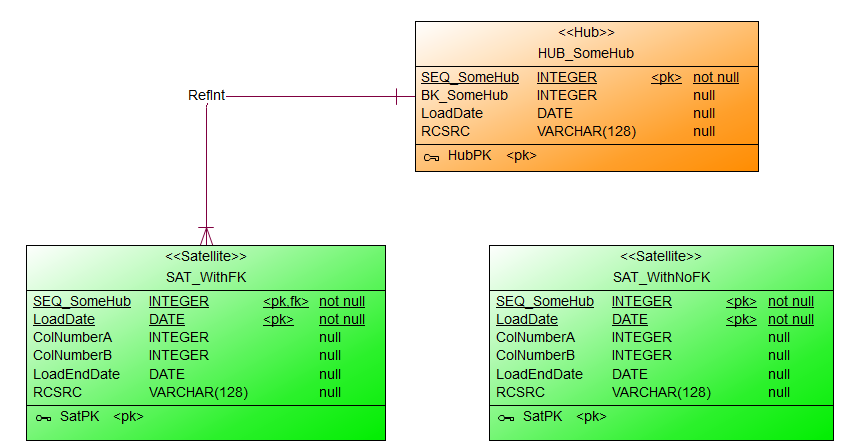
Immer wieder kommt in Projekten die Frage auf, besser gesagt die Diskussion, ob Constraints in der Datenbank physisch sinnvoll sind oder nicht. Meist gibt es Vorgaben von DBAs oder durchsetzungsstarken ETLern, die eine generelle Abneigung gegen Constraints zu haben scheinen, dass Constraints nicht erwünscht sind. OK, diese Woche wurde mir wieder das Gegenteil bewiesen. Doch wie heißt es so schön: Ausnahmen...
Auf dem #WWDVC und im Advanced Data Vault 2.0 Boot Camp haben wir ebenfalls über dieses Phänomen gesprochen. Das scheint weltweit zu existieren. Dazu hat kurz nach dem #WWDVC auch Kent Graziano einen Blogpost verfasst. Auf LinkedIn gab es dazu einige Kommentare.
Gut, wie argumentiert man am besten, bzw. was sind eigentlich die Vor- und Nachteile Constraints zu verwenden?