
You may have received an e-mail invitation from EXASOL or from ITGAIN inviting you to our forthcoming webinar, such as this:
Do you have difficulty incorporating different data sources into your current database? Would you like an agile development environment? Or perhaps you are using Data Vault for data modeling and are facing performance issues?
If so, then attend our free webinar entitled “Data Vault Modeling with EXASOL: High performance and agile data warehousing.” The 60-minute webinar takes place on July 15 from 10:00 to 11:00 am CEST.
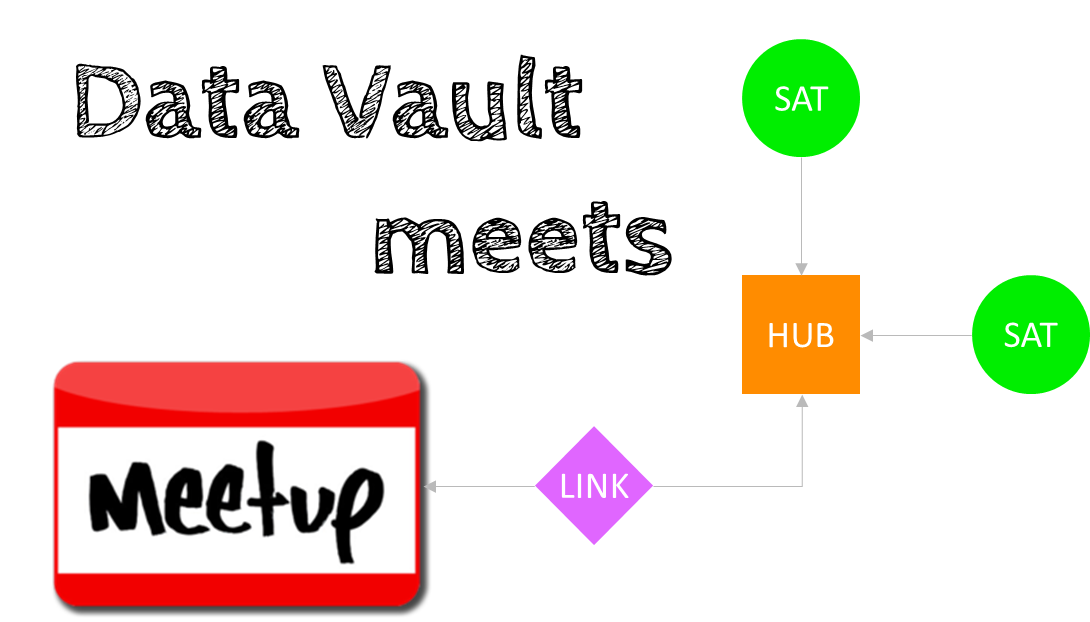
I reactivated my Meetup Data Vault Interest Group this week. Long time ago I was thinking about a table of fellow regulars to network with other, let’s call them Data Vaulters. It should be a relaxed get-together, no business driven presentation or even worse advertisement for XYZ tool, consulting or any flavor of Data Vault. The feedback of many people was that they want something different to the existing Business Intelligence Meetings. So, here it is!
Some time ago a customers asked me how to load easy and simple some (test)data into their database XYZ (chose the one of your choice and replace XYZ) to test their new developed Data Vault logistic processes.
The point was: They don’t want to use all this ETL-tool and IT-processes overhead just to some small test in their own environment. If this this is well done from a data governance perspective? Well, that’s not part of this blogpost. Just do this kind of thingis only in your development environment.
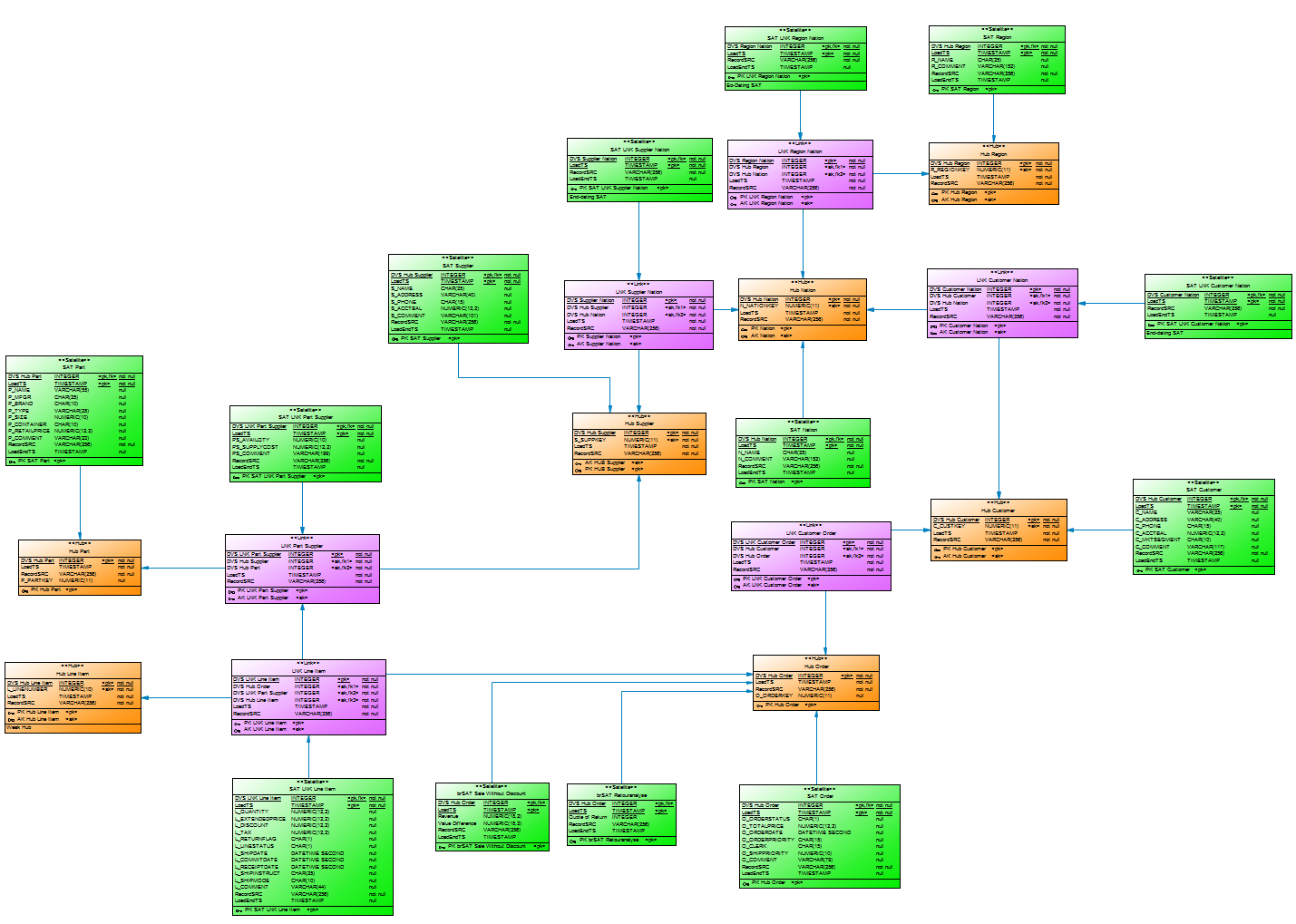
Over the last few weeks, Mathias Brink and I have worked hard on the topic of Data Vault on EXASOL.
Our (simple) question: How does EXASOL perform with Data Vault?
First, we had to decide what kind of data to run performance tests against in order to get a feeling for the power of this combination. And we decided to use the well-known TPC-H benchmark created by the non-profit organisation TPC.
Second, we built a (simple) Data Vault model and loaded 500 GB of data into the installed model. And to be honest, it was not the best model. On top of it we built a virtual TPC-H data model to execute the TPC-H SQLs in order to analyse performance.
Seite 5 von 8