Data Warehouse
-
13 Tipps, um Ihr Data-Vault-Projekt scheitern zu lassen

Oder wie Sie erfolgreich jede Ebene des Data Warehouse torpedieren
Sie sind erfolgsverwöhnt und haben das ewige Schulterklopfen satt? Sie wollen nicht auch noch bei Ihrem ersten Versuch zur Umsetzung eines Data-Vault-Projekts so erfolgreich sein, dass alle Kollegen neidisch werden?
-
13 tips to make your Data Vault project fail

Or how to successfully destroy every level of the data warehouse
Are you pampered with success and tired of the eternal pat on the back? You don't want to be so successful with your first attempt at implementing a Data Vault project that all your colleagues become jealous?
-
A comment
In recent weeks I have read so many pessimistic and negative articles and comments in the social media about the state of data modeling in companies in Germany, but also worldwide.
Why? I don't know. I can't understand it.
I know many companies that invest a lot of time in data modeling because they have understood the added value. I know many companies that initially rejected data modeling as a whole, but understood its benefits through convincing and training.
Isn't it the case that we (consultants, managers, project managers, subject-matter experts, etc.) should have a positive influence on data modeling? To support our partners in projects in such a way that data modeling becomes a success? If we ourselves do not believe that data modeling is a success, then who does?
-
Academy
With our TEDAMOH Academy we offer various seminars, trainings and workshops to support and develop continuous learning in your daily business.
You can either extend you theoretical knowledge by attending a seminar or work in practically oriented workshops to acquire knowledge by yourself. To train the usage of a new software or method, such as dealing with temporal data, it is best to have a closer look at the training area.
-
Agile Data Warehousing bei Binck

Im April 2013 war ich wieder beim Matter-Programm, Data Vault Architecture, in den Niederlanden wo ich Tom Breur kennen lernen durfte.
In einer angeregten Diskussion über die Automatisierung von Data Warehousing mit Data Vault und der Eignung von Projektmethoden dafür lud Tom mich und Oliver Cramer zu einem Besuch von einem Kunden von sich ein: Der BinckBank.
Tom Breur: “The best Agile BI shops I have ever seen.”
Am 24. September 2013 war es dann soweit. Wir besuchten gemeinsam mit Tom die BinckBanck in Amsterdam und schauten uns das Agile Data Warehouse an, welches mit Data Vault aufgebaut wurde. Wir trafen uns mit dem BICC-Team, um über die Entstehungsgeschichte, die Umsetzung, die Herausforderungen und die Erfolgsfaktoren zu sprechen.
-
An open and honest feedback on “13 tips …”

A few weeks ago I received a surprisingly open and honest feedback on my recently published article "13 tips...". I never ever expected that! After a short email exchange, I was allowed to publish the feedback anonymously. Below is the incredible feedback[3]. You see, you are not alone with the challenges of a Data Vault project:
Hi Dirk
Thanks for sending me the English version of the paper. I'm based in […] [1] and Data Vault is not generally established here yet. -
Articles
All articles I wrote about data warehousing, Data Vault, data modeling and more.
Enjoy reading and your comments are welcome.
-
Bitemporal Data
If everything would happen at the same time, there would be no need to store historic data. We, the consumers of data, would know each and everything at the same instant. Beside all the other philosophical impacts, if time wouldn’t exists, is data still necessary?
(Un)fortunately time exists and data architects, data modelers and developers have to deal with it in the world of information technology.
In this category about temporal data I will collect all my blogposts about this fancy topic.
-
Bitemporal Data Marts

Since more than 15 years I’m working with bitemporal data in Data Warehouse solutions. Meanwhile it is easy to design, build and populate tables for bitemporal data. But how to design and build bitemporal dimensional modeled Data Marts was new to me. Dirk Lerner does a very good job in explaining complex bitemporal stuff.
-
Bitemporale Data Marts

Seit mehr als 15 Jahren arbeite ich mit bitemporalen Daten in Data Warehouse Lösungen. Mittlerweile ist es einfach, Tabellen für bitemporale Daten zu entwerfen, zu erstellen und zu befüllen. Aber wie man bitemporale dimensional modellierte Data Marts entwirft und aufbaut, war mir neu. Dirk Lerner leistet eine sehr gute Arbeit bei der Erklärung komplexer bitemporaler Daten.
-
Change default value

At FastChangeCo, the data modelers within the Data Management Center of Excellence (DMCE) team are constantly designing new database objects to store data. One of the data modelers on the team is Xuefang Kaya. When she takes a new user story/task, she usually models multiple tables, their columns, and specifies a data type for each column.
-
Coaching Serie

/ SECRET SPICE - COACHING Serie
Coaching - Wie denn nun?
In loser Folge veröffentliche ich meine Gedanken und Erfahrungen rund um Datenmodellierung, temporale Daten oder viele andere Dinge aus der Welt des Coachings. Dazu gehören für mich Lösungsansätze unterschiedlichster Art, die manchmal generell, manchmal ausschließlich für eine bestimmte Situation geeignet sind.
Sehr oft wichtig und nicht zu vernachlässigen sind die fachlichen Anforderungen, die den Lösungsansätzen zugrunde liegen.
Wie die bereits veröffentlichte Serie zum PowerDesigner und die Serie zu temporalen Daten ist diese Serie für mich eine Art, kleine Schätze aus meiner Coaching-Welt, das ‘Secret Spice’, mit euch zu teilen.
In dieser Serie werdet ihr wahrscheinlich nicht so oft wie in den anderen Serien auf die Teammitglieder des Data Management Center of Excellence (DMCE) meines Lieblingskunden FastChangeCoTM treffen.
-
Coaching Series
/ SECRET SPICE - COACHING SerieS
Coaching - How to do it?
In loose order I publish my thoughts and experiences around data modeling, temporal data or many other things from the world of coaching. For me, this includes approaches to solutions of the most varying kinds, which are sometimes suitable in general, sometimes exclusively for a specific situation.
Very often important and not to be disregarded are the business requirements on which the approaches to a solution are based.
Like the already published series on PowerDesigner and the series on temporal data, this series is a way for me to share with you little treasures from my coaching world, the 'Secret Spice'.
In this series, you probably won't run into the Data Management Center of Excellence (DMCE) team members from my favorite customer, FastChangeCoTM, as often as in the other series.
-
Constraints im Data Vault
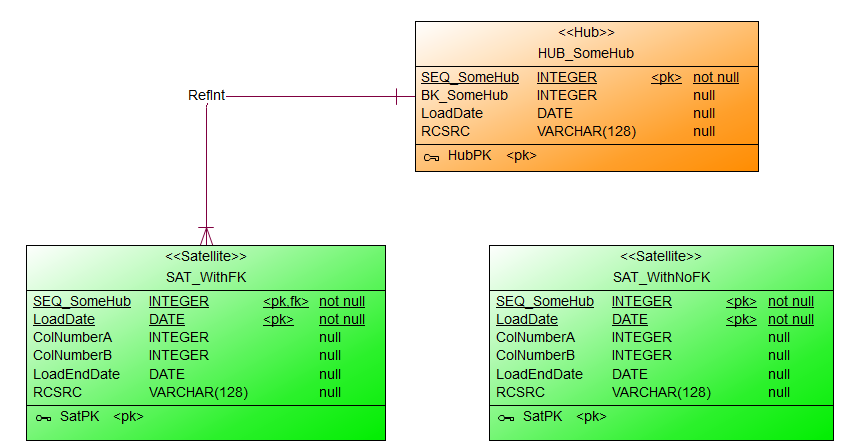
Immer wieder kommt in Projekten die Frage auf, besser gesagt die Diskussion, ob Constraints in der Datenbank physisch sinnvoll sind oder nicht. Meist gibt es Vorgaben von DBAs oder durchsetzungsstarken ETLern, die eine generelle Abneigung gegen Constraints zu haben scheinen, dass Constraints nicht erwünscht sind. OK, diese Woche wurde mir wieder das Gegenteil bewiesen. Doch wie heißt es so schön: Ausnahmen...
Auf dem #WWDVC und im Advanced Data Vault 2.0 Boot Camp haben wir ebenfalls über dieses Phänomen gesprochen. Das scheint weltweit zu existieren. Dazu hat kurz nach dem #WWDVC auch Kent Graziano einen Blogpost verfasst. Auf LinkedIn gab es dazu einige Kommentare.
Gut, wie argumentiert man am besten, bzw. was sind eigentlich die Vor- und Nachteile Constraints zu verwenden?
-
Customize table comments
In several projects, FastChangeCo's data modelers on the Data Management Center of Excellence (DMCE) team had an issue with the way PowerDesigner generates comments for tables and columns for the SQL Server database. Xuefang Kaya (one of the data modelers on the team), asked about the problems, says to the DMCE team:
-
Das Ziel: ganzheitliche Gestaltung

Data Vault im Einsatz beim Gutenberg RechenzentrumIm Rahmen einer umfassenden Neugestaltung entsteht beim Gutenberg Rechenzentrum in Hannover eine neue Data-Warehouse-Architektur für ein Standardprodukt, das als Analyse-Komponente für die ERP-Verlagslösung des GRZ zum Einsatz kommt. Heterogene Kundenanforderungen, Customizing der ERP-Komponenten sowie ein gefoderter hoher Grad an Flexibilität und kundenindividueller Ausgestaltung spiegeln sich in einer Hub-and-Spoke-Architektur mit einem als Data Vault modellierten Core Warehouse und mehrdimensionalen Data Marts wider.
-
Data Architecture
-
Data Model Scorecard
Objective review and data quality goals of data models
Did you ever ask yourself which score your data model would achieve? Could you imagine 90%, 95% or even 100% across 10 categories of objective criteria?
No?
Yes?Either way, if you answered with “no” or “yes”, recommend using something to test the quality of your data model(s). For years there have been methods to test and ensure quality in software development, like ISTQB, IEEE, RUP, ITIL, COBIT and many more. In data warehouse projects I observed test methods testing everything: loading processes (ETL), data quality, organizational processes, security, …
But data models? Never! But why? -
Data Modeling Zone EU/US 19 #DMZone

OK, for those of you who just want to grab a promotion code... I'll make it short 😂:
TEDAMOH
As a speaker at both conferences I give you 15% on the DMZ EU and 20% on the DMZ US. You can register here.
For those of you who are also interested in what I'm going to talk about, a few more informations:
-
Data Modeling Zone Europe 2015

Do you want to learn something about data modelling with Steve Hoberman? You want to explore new methods like Data Vault 2.0, Anchor Modeling, Data Design, DMBOK and many more? E.g. a keynote where Dan Linstedt, Lars Rönnbäck and Hans Hultgren talks together, and another one with Bill Inmon?