In July 2016 Mathias Brink and I had given a webinar how to implement Data Vault on a EXASOL database. Read more about in my previous blogpost or watch the recording on Youtube.
Afterward I became a lot of questions per our webinar. I’ll now answer all questions I got till today. If you have further more questions feel free to ask via my contact page,via Twitter, or write a comment right here.
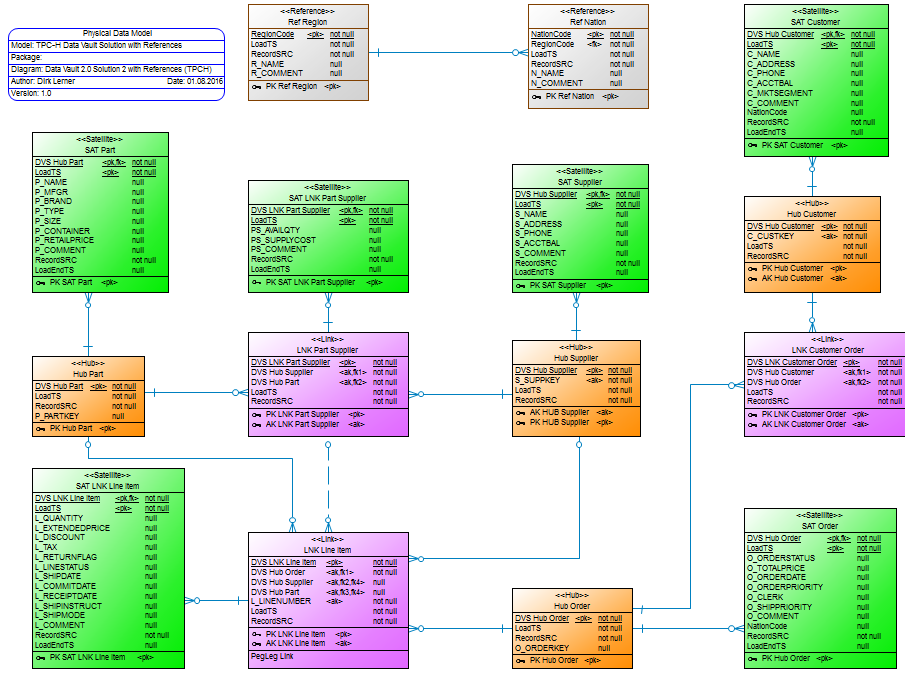
On July 15, Mathias Brink and I ran a webinar about Data Vault on EXASOL, modeling and implementation. The webinar started with an overview of the concepts of Data Vault Modeling and how Data Vault Modeling enables agile development cycles. Afterwards, we showed a demo that transformed the TPC-H data model into a Data Vault data model and how you can then query the data out of the Data Vault data model. The results were then compared with the original queries of the TPC-H.

You may have received an e-mail invitation from EXASOL or from ITGAIN inviting you to our forthcoming webinar, such as this:
Do you have difficulty incorporating different data sources into your current database? Would you like an agile development environment? Or perhaps you are using Data Vault for data modeling and are facing performance issues?
If so, then attend our free webinar entitled “Data Vault Modeling with EXASOL: High performance and agile data warehousing.” The 60-minute webinar takes place on July 15 from 10:00 to 11:00 am CEST.
I reactivated my Meetup Data Vault Interest Group this week. Long time ago I was thinking about a table of fellow regulars to network with other, let’s call them Data Vaulters. It should be a relaxed get-together, no business driven presentation or even worse advertisement for XYZ tool, consulting or any flavor of Data Vault. The feedback of many people was that they want something different to the existing Business Intelligence Meetings. So, here it is!
Seite 4 von 8